
{kind=link}

Picture by Creator
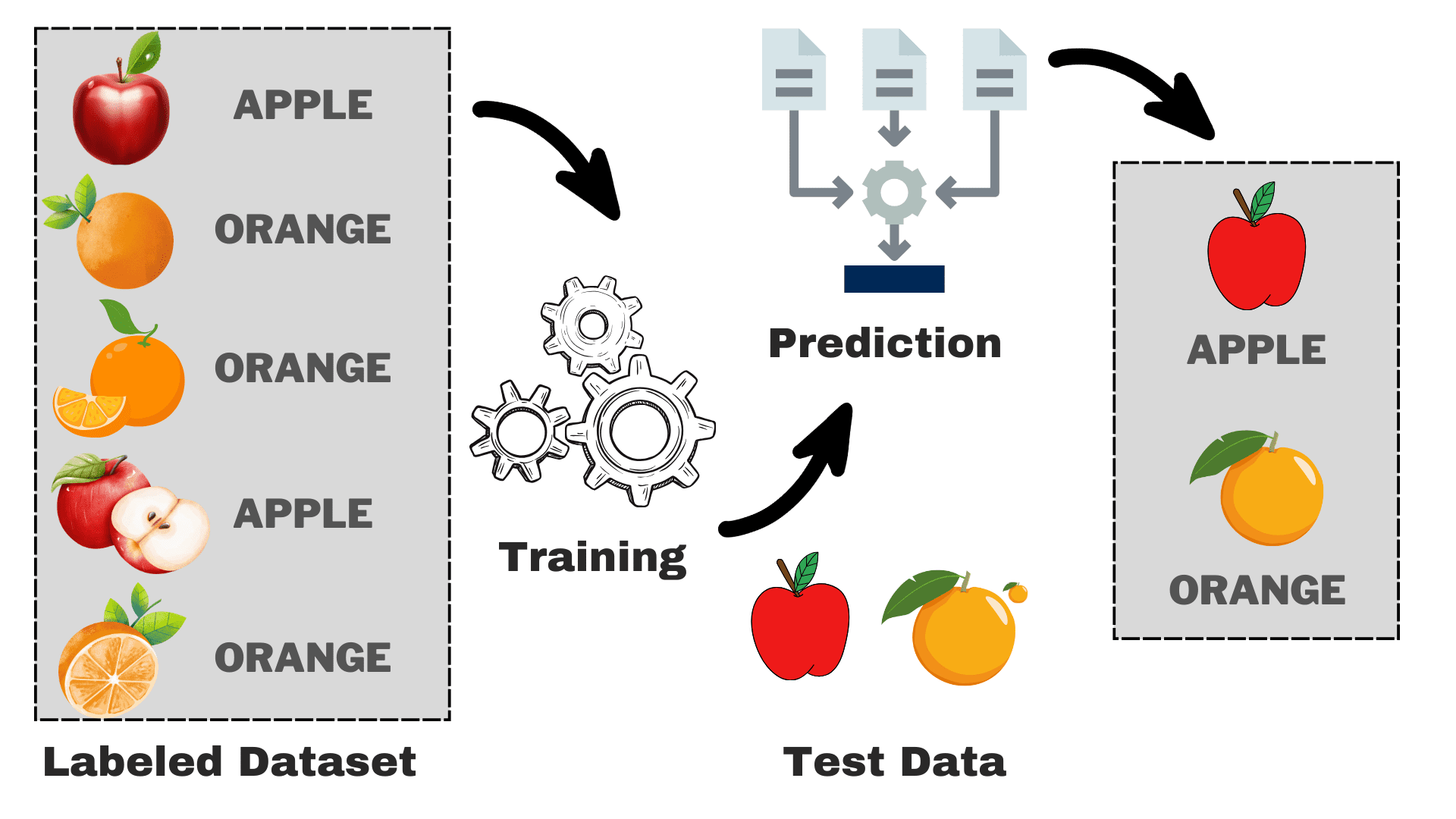
Supervised is a subcategory of machine studying wherein the pc learns from the labeled dataset containing each the enter in addition to the proper output. It tries to search out the mapping perform that relates the enter (x) to the output (y). You may consider it as instructing your youthful brother or sister tips on how to acknowledge completely different animals. You’ll present them some footage (x) and inform them what every animal is known as (y). After a sure time, they may be taught the variations and can have the ability to acknowledge the brand new image appropriately. That is the essential instinct behind supervised studying. Earlier than transferring ahead, let’s take a deeper have a look at its workings.
How Does Supervised Studying Work?
Picture by Creator
Suppose that you simply need to construct a mannequin that may differentiate between apples and oranges primarily based on some traits. We are able to break down the method into the next duties:
- Information Assortment: Collect a dataset with footage of apples and oranges, and every picture is labeled as both “apple” or “orange.”
- Mannequin Choice: Now we have to select the suitable classifier right here typically generally known as the suitable supervised machine studying algorithm on your activity. It is rather like selecting the correct glasses that may make it easier to see higher
- Coaching the Mannequin: Now, you feed the algorithm with the labeled photos of apples and oranges. The algorithm appears to be like at these footage and learns to acknowledge the variations, equivalent to the colour, form, and dimension of apples and oranges.
- Evaluating & Testing: To test in case your mannequin is working appropriately, we are going to feed some unseen footage to it and examine the predictions with the precise one.
Supervised studying will be divided into two primary sorts:
Classification
In classification duties, the first goal is to assign information factors to particular classes from a set of discrete lessons. When there are solely two attainable outcomes, equivalent to “sure” or “no,” “spam” or “not spam,” “accepted” or “rejected,” it’s known as binary classification. Nonetheless, when there are greater than two classes or lessons concerned, like grading college students primarily based on their marks (e.g., A, B, C, D, F), it turns into an instance of a multi-classification drawback.
Regression
For regression issues, you are attempting to foretell a steady numerical worth. For instance, you is likely to be thinking about predicting your remaining examination scores primarily based in your previous efficiency within the class. The expected scores can span any worth inside a selected vary, sometimes from 0 to 100 in our case.
Now, we’ve got a primary understanding of the general course of. We are going to discover the favored supervised machine studying algorithms, their utilization, and the way they work:
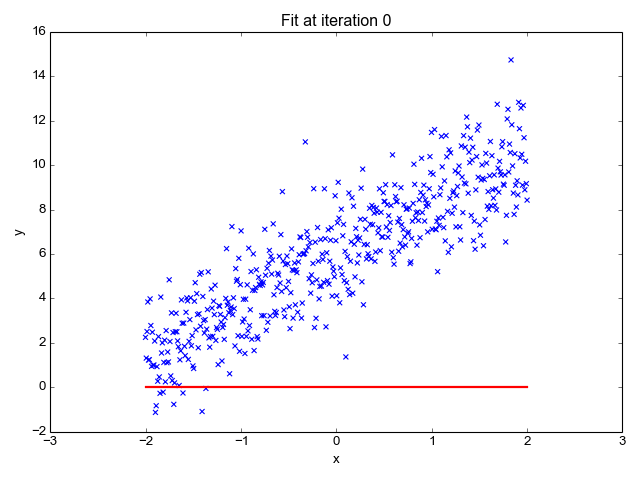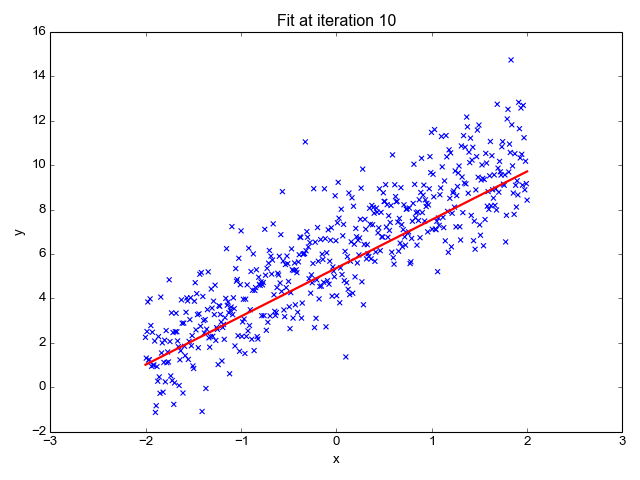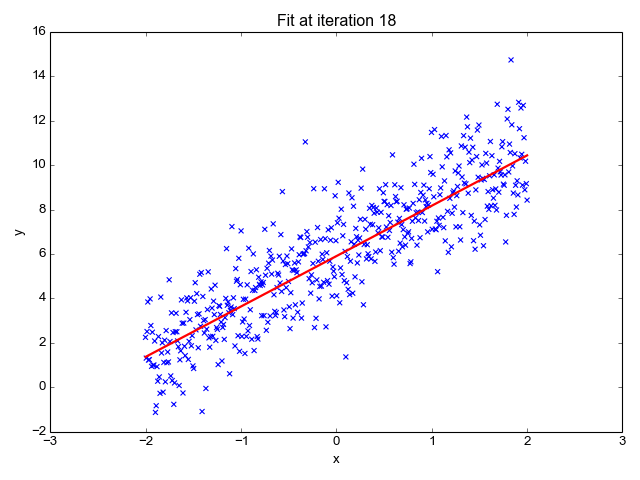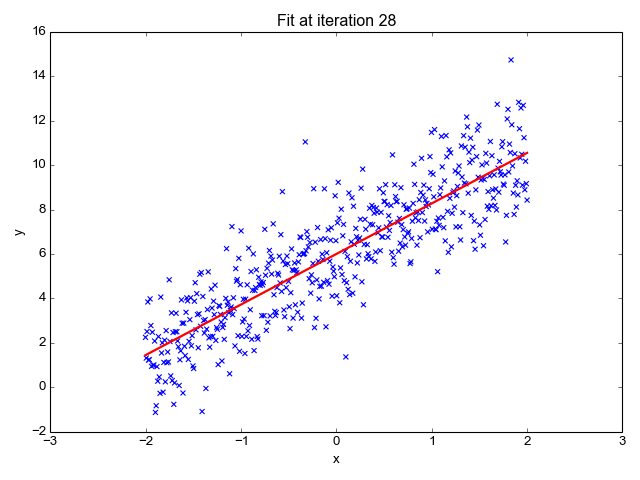
1. Linear Regression
Because the title suggests, it’s used for regression duties like predicting inventory costs, forecasting the temperature, estimating the chance of illness development, and many others. We attempt to predict the goal (dependent variable) utilizing the set of labels (impartial variables). It assumes that we’ve got a linear relationship between our enter options and the label. The central concept revolves round predicting the best-fit line for our information factors by minimizing the error between our precise and predicted values. This line is represented by the equation:
The place,
- Y Predicted output.
- X = Enter function or function matrix in a number of linear regression
- b0 = Intercept (the place the road crosses the Y-axis).
- b1 = Slope or coefficient that determines the road’s steepness.
It estimates the slope of the road (weight) and its intercept(bias). This line can be utilized additional to make predictions. Though it’s the easiest and helpful mannequin for growing the baselines it’s extremely delicate to outliers that will affect the place of the road.
Gif on Primo.ai
2. Logistic Regression
Though it has regression in its title, however is essentially used for binary classification issues. It predicts the likelihood of a optimistic final result (dependent variable) which lies within the vary of 0 to 1. By setting a threshold (normally 0.5), we classify information factors: these with a likelihood better than the brink belongs to the optimistic class, and vice versa. Logistic regression calculates this likelihood utilizing the sigmoid perform utilized to the linear mixture of the enter options which is specified as:
The place,
- P(Y=1) = Chance of the information level belonging to the optimistic class
- X1 ,… ,Xn = Enter Options
- b0,….,bn = Enter weights that the algorithm learns throughout coaching
This sigmoid perform is within the type of S like curve that transforms any information level to a likelihood rating throughout the vary of 0-1. You may see the under graph for a greater understanding.

Picture on Wikipedia
A more in-depth worth to 1 signifies a better confidence within the mannequin in its prediction. Similar to linear regression, it’s recognized for its simplicity however we can’t carry out the multi-class classification with out modification to the unique algorithm.
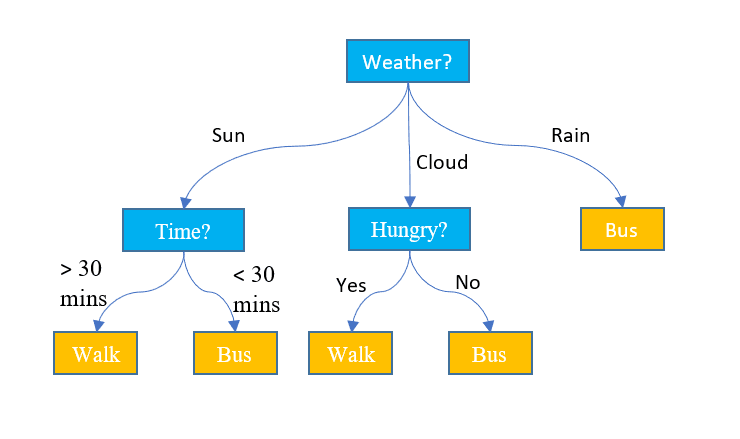
3. Choice Bushes
Not like the above two algorithms, resolution timber can be utilized for each classification and regression duties. It has a hierarchical construction identical to the flowcharts. At every node, a choice in regards to the path is made primarily based on some function values. The method continues except we attain the final node that depicts the ultimate resolution. Right here is a few primary terminology that it’s essential to pay attention to:
- Root Node: The highest node containing all the dataset is known as the foundation node. We then choose the most effective function utilizing some algorithm to separate the dataset into 2 or extra sub-trees.
- Inner Nodes: Every Inner node represents a selected function and a choice rule to resolve the following attainable route for an information level.
- Leaf Nodes: The ending nodes that signify a category label are known as leaf nodes.
It predicts the continual numerical values for the regression duties. As the scale of the dataset grows, it captures the noise resulting in overfitting. This may be dealt with by pruning the choice tree. We take away branches that do not considerably enhance the accuracy of our selections. This helps hold our tree centered on a very powerful components and prevents it from getting misplaced within the particulars.
Picture by Jake Hoare on Displayr
4. Random Forest
Random forest may also be used for each the classification and the regression duties. It’s a group of resolution timber working collectively to make the ultimate prediction. You may consider it because the committee of consultants making a collective resolution. Right here is the way it works:
- Information Sampling: As an alternative of taking all the dataset without delay, it takes the random samples through a course of referred to as bootstrapping or bagging.
- Characteristic Choice: For every resolution tree in a random forest, solely the random subset of options is taken into account for the decision-making as an alternative of the whole function set.
- Voting: For classification, every resolution tree within the random forest casts its vote and the category with the best votes is chosen. For regression, we common the values obtained from all timber.
Though it reduces the impact of overfitting brought on by particular person resolution timber, however is computationally costly. One phrase that you’ll learn ceaselessly within the literature is that the random forest is an ensemble studying methodology, which implies it combines a number of fashions to enhance general efficiency.
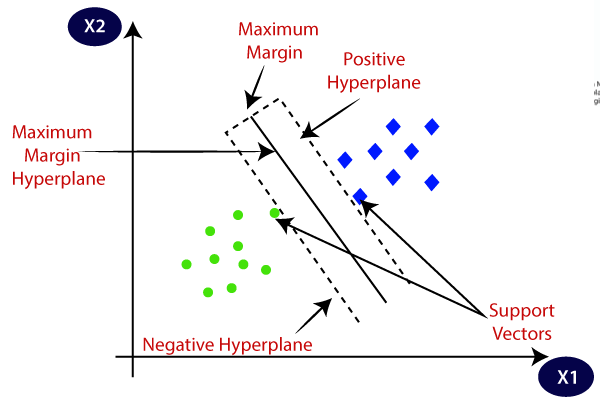
5. Help Vector Machines (SVM)
It’s primarily used for classification issues however can deal with regression duties as effectively. It tries to search out the most effective hyperplane that separates the distinct lessons utilizing the statistical strategy, in contrast to the probabilistic strategy of logistic regression. We are able to use the linear SVM for the linearly separable information. Nonetheless, a lot of the real-world information is non-linear and we use the kernel tips to separate the lessons. Let’s dive deep into the way it works:
- Hyperplane Choice: In binary classification, SVM finds the most effective hyperplane (2-D line) to separate the lessons whereas maximizing the margin. Margin is the gap between the hyperplane and the closest information factors to the hyperplane.
- Kernel Trick: For linearly inseparable information, we make use of a kernel trick that maps the unique information house right into a high-dimensional house the place they are often separated linearly. Widespread kernels embody linear, polynomial, radial foundation perform (RBF), and sigmoid kernels.
- Margin Maximization: SVM additionally tries to enhance the generalization of the mannequin by growing the maximizing margin.
- Classification: As soon as the mannequin is skilled, the predictions will be made primarily based on their place relative to the hyperplane.
SVM additionally has a parameter referred to as C that controls the trade-off between maximizing the margin and conserving the classification error to a minimal. Though they’ll deal with high-dimensional and non-linear information effectively, selecting the best kernel and hyperparameter shouldn’t be as straightforward because it appears.
Picture on Javatpoint
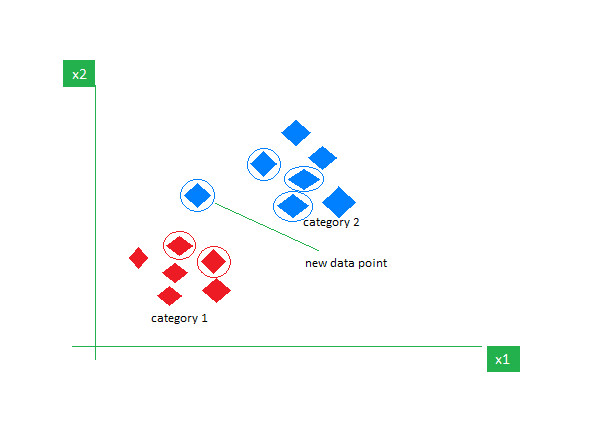
6. k-Nearest Neighbors (k-NN)
Okay-NN is the best supervised studying algorithm principally used for classification duties. It doesn’t make any assumptions in regards to the information and assigns the brand new information level a class primarily based on its similarity with the prevailing ones. In the course of the coaching section, it retains all the dataset as a reference level. It then calculates the gap between the brand new information level and all the prevailing factors utilizing a distance metric (Eucilinedain distance e.g.). Based mostly on these distances, it identifies the Okay nearest neighbors to those information factors. We then depend the prevalence of every class within the Okay nearest neighbors and assign probably the most ceaselessly showing class as the ultimate prediction.
Picture on GeeksforGeeks
Choosing the proper worth of Okay requires experimentation. Though it’s sturdy to noisy information it’s not appropriate for prime dimensional datasets and has a excessive price related because of the calculation of the gap from all information factors.
As I conclude this text, I might encourage the readers to discover extra algorithms and attempt to implement them from scratch. This may strengthen your understanding of how issues are working beneath the hood. Listed here are some further sources that will help you get began:
Kanwal Mehreen is an aspiring software program developer with a eager curiosity in information science and functions of AI in drugs. Kanwal was chosen because the Google Technology Scholar 2022 for the APAC area. Kanwal likes to share technical data by writing articles on trending matters, and is keen about bettering the illustration of ladies in tech trade.