
{kind=link}
Sponsored Content material
By Jim Dowling, Co-Founder & CEO, Hopsworks
This text introduces a unified architectural sample for constructing each Batch and Actual-Time machine studying (ML) Techniques. We name it the FTI (Function, Coaching, Inference) pipeline structure. FTI pipelines break up the monolithic ML pipeline into 3 unbiased pipelines, every with clearly outlined inputs and outputs, the place every pipeline may be developed, examined, and operated independently. For a historic perspective on the evolution of the FTI Pipeline structure, you may learn the complete in-depth psychological map for MLOps article.
Lately, Machine Studying Operations (MLOps) has gained mindshare as a growth course of, impressed by DevOps ideas, that introduces automated testing, versioning of ML property, and operational monitoring to allow ML methods to be incrementally developed and deployed. Nonetheless, present MLOps approaches usually current a posh and overwhelming panorama, leaving many groups struggling to navigate the trail from mannequin growth to manufacturing. On this article, we introduce a recent perspective on constructing ML methods via the idea of FTI pipelines. The FTI structure has empowered numerous builders to create sturdy ML methods with ease, lowering cognitive load, and fostering higher collaboration throughout groups. We delve into the core ideas of FTI pipelines and discover their functions in each batch and real-time ML methods.
The FTI method for this architectural sample has been used to construct lots of of ML methods. The sample is as follows – a ML system consists of three independently developed and operated ML pipelines:
- a characteristic pipeline that takes as enter uncooked information that it transforms into options (and labels)
- a coaching pipeline that takes as enter options (and labels) and outputs a skilled mannequin, and
- an inference pipeline that takes new characteristic information and a skilled mannequin and makes predictions.
On this FTI, there isn’t any single ML pipeline. The confusion about what the ML pipeline does (does it characteristic engineer and prepare fashions or additionally do inference or simply a type of?) disappears. The FTI structure applies to each batch ML methods and real-time ML methods.

Determine 1: The Function/Coaching/Inference (FTI) pipelines for constructing ML Techniques
The characteristic pipeline generally is a batch program or a streaming program. The coaching pipeline can output something from a easy XGBoost mannequin to a parameter-efficient fine-tuned (PEFT) large-language mannequin (LLM), skilled on many GPUs. Lastly, the inference pipeline generally is a batch program that produces a batch of predictions to a web-based service that takes requests from purchasers and returns predictions in real-time.
One main benefit of FTI pipelines is that it’s an open structure. You should use Python, Java or SQL. If you have to do characteristic engineering on massive volumes of knowledge, you should use Spark or DBT or Beam. Coaching will sometimes be in Python utilizing some ML framework, and batch inference may very well be in Python or Spark, relying in your information volumes. On-line inference pipelines are, nevertheless, practically all the time in Python as fashions are sometimes coaching with Python.
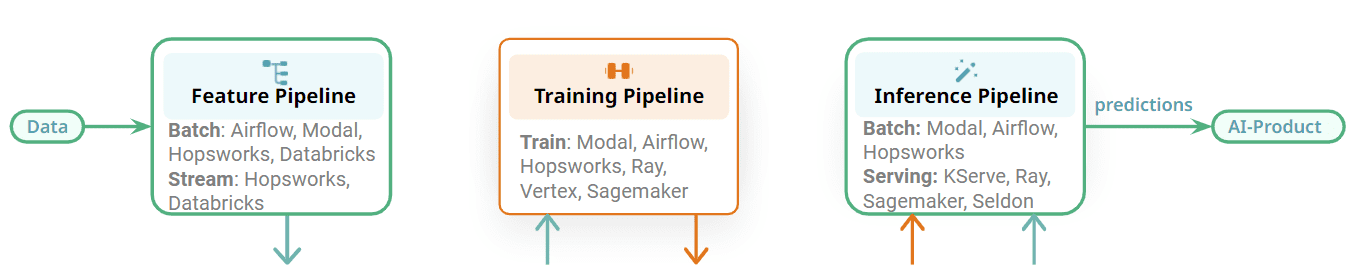
Determine 2: Select the most effective orchestrator to your ML pipeline/service.
The FTI pipelines are additionally modular and there’s a clear interface between the completely different phases. Every FTI pipeline may be operated independently. In comparison with the monolithic ML pipeline, completely different groups can now be accountable for growing and working every pipeline. The impression of that is that for orchestration, for instance, one staff might use one orchestrator for a characteristic pipeline and a unique staff might use a unique orchestrator for the batch inference pipeline. Alternatively, you might use the identical orchestrator for the three completely different FTI pipelines for a batch ML system. Some examples of orchestrators that can be utilized in ML methods embody general-purpose, feature-rich orchestrators, equivalent to Airflow, or light-weight orchestrators, equivalent to Modal, or managed orchestrators provided by characteristic platforms.
A few of the FTI pipelines, nevertheless, is not going to want orchestration. Coaching pipelines may be run on-demand, when a brand new mannequin is required. Streaming characteristic pipelines and on-line inference pipelines run repeatedly as companies, and don’t require orchestration. Flink, Spark Streaming, and Beam are run as companies on platforms equivalent to Kubernetes, Databricks, or Hopsworks. On-line inference pipelines are deployed with their mannequin on mannequin serving platforms, equivalent to KServe (Hopsworks), Seldon, Sagemaker, and Ray. The primary takeaway right here is that the ML pipelines are modular with clear interfaces, enabling you to decide on the most effective expertise for operating your FTI pipelines.
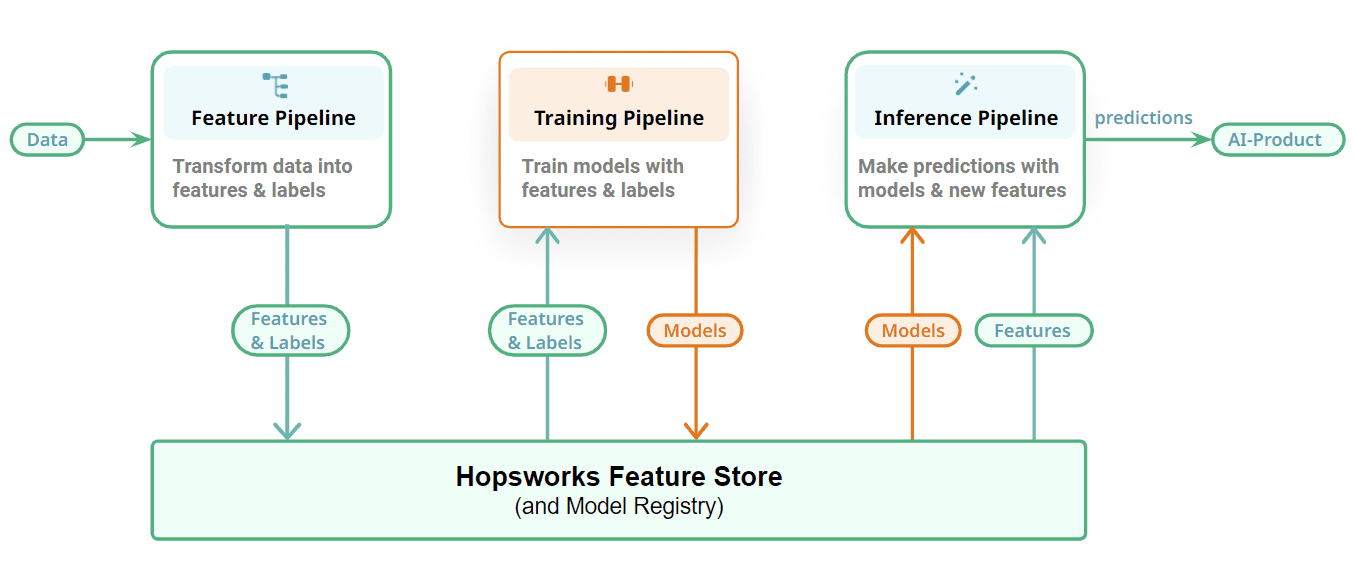
Determine 3: Join your ML pipelines with a Function Retailer and Mannequin Registry
Lastly, we present how we join our FTI pipelines along with a stateful layer to retailer the ML artifacts – options, coaching/take a look at information, and fashions. Function pipelines retailer their output, options, as DataFrames within the characteristic retailer. Incremental tables retailer every new replace/append/delete as separate commits utilizing a desk format (we use Apache Hudi in Hopsworks). Coaching pipelines learn point-in-time constant snapshots of coaching information from Hopsworks to coach fashions with and output the skilled mannequin to a mannequin registry. You may embody your favourite mannequin registry right here, however we’re biased in direction of Hopsworks’ mannequin registry. Batch inference pipelines additionally learn point-in-time constant snapshots of inference information from the characteristic retailer, and produce predictions by making use of the mannequin to the inference information. On-line inference pipelines compute on-demand options and browse precomputed options from the characteristic retailer to construct a characteristic vector that’s used to make predictions in response to requests by on-line functions/companies.
Function Pipelines
Function pipelines learn information from information sources, compute options and ingest them to the characteristic retailer. A few of the questions that should be answered for any given characteristic pipeline embody:
- Is the characteristic pipeline batch or streaming?
- Are characteristic ingestions incremental or full-load operations?
- What framework/language is used to implement the characteristic pipeline?
- Is there information validation carried out on the characteristic information earlier than ingestion?
- What orchestrator is used to schedule the characteristic pipeline?
- If some options have already been computed by an upstream system (e.g., a knowledge warehouse), how do you forestall duplicating that information, and solely learn these options when creating coaching or batch inference information?
Coaching Pipelines
In coaching pipelines a few of the particulars that may be found on double-clicking are:
- What framework/language is used to implement the coaching pipeline?
- What experiment monitoring platform is used?
- Is the coaching pipeline run on a schedule (in that case, what orchestrator is used), or is it run on-demand (e.g., in response to efficiency degradation of a mannequin)?
- Are GPUs wanted for coaching? If sure, how are they allotted to coaching pipelines?
- What characteristic encoding/scaling is completed on which options? (We sometimes retailer characteristic information unencoded within the characteristic retailer, in order that it may be used for EDA (exploratory information evaluation). Encoding/scaling is carried out in a constant method coaching and inference pipelines). Examples of characteristic encoding methods embody scikit-learn pipelines or declarative transformations in characteristic views (Hopsworks).
- What mannequin analysis and validation course of is used?
- What mannequin registry is used to retailer the skilled fashions?
Inference Pipelines
Inference pipelines are as numerous because the functions they AI-enable. In inference pipelines, a few of the particulars that may be found on double-clicking are:
- What’s the prediction shopper – is it a dashboard, on-line software – and the way does it eat predictions?
- Is it a batch or on-line inference pipeline?
- What kind of characteristic encoding/scaling is completed on which options?
- For a batch inference pipeline, what framework/language is used? What orchestrator is used to run it on a schedule? What sink is used to eat the predictions produced?
- For a web-based inference pipeline, what mannequin serving server is used to host the deployed mannequin? How is the net inference pipeline carried out – as a predictor class or with a separate transformer step? Are GPUs wanted for inference? Is there a SLA (service-level agreements) for a way lengthy it takes to answer prediction requests?
The present mantra is that MLOps is about automating steady integration (CI), steady supply (CD), and steady coaching (CT) for ML methods. However that’s too summary for a lot of builders. MLOps is de facto about continuous growth of ML-enabled merchandise that evolve over time. The obtainable enter information (options) adjustments over time, the goal you are attempting to foretell adjustments over time. You should make adjustments to the supply code, and also you need to be sure that any adjustments you make don’t break your ML system or degrade its efficiency. And also you need to speed up the time required to make these adjustments and take a look at earlier than these adjustments are mechanically deployed to manufacturing.
So, from our perspective, a extra pithy definition of MLOps that allows ML Techniques to be safely advanced over time is that it requires, at a minimal, automated testing, versioning, and monitoring of ML artifacts. MLOps is about automated testing, versioning, and monitoring of ML artifacts.
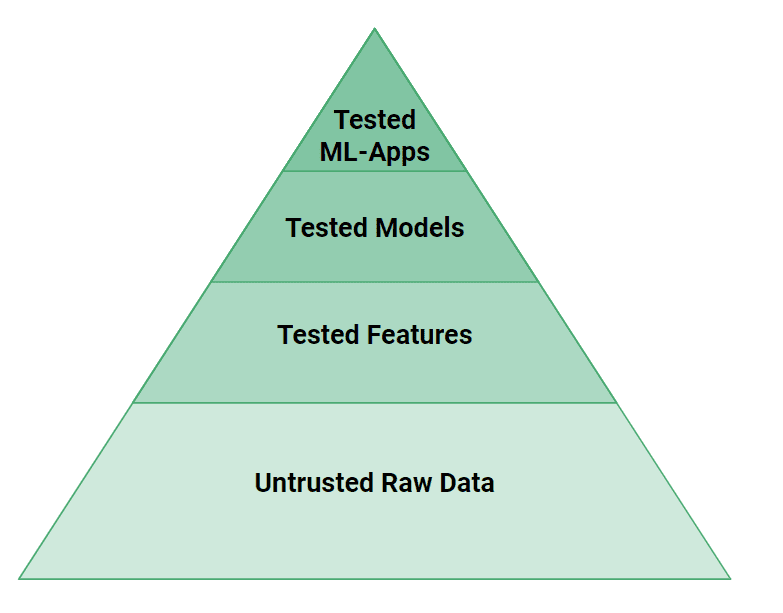
Determine 4: The testing pyramid for ML Artifacts
In determine 4, we will see that extra ranges of testing are wanted in ML methods than in conventional software program methods. Small bugs in information or code can simply trigger a ML mannequin to make incorrect predictions. From a testing perspective, if internet functions are propeller-driven airplanes, ML methods are jet-engines. It takes vital engineering effort to check and validate ML Techniques to make them protected!
At a excessive degree, we have to take a look at each the source-code and information for ML Techniques. The options created by characteristic pipelines can have their logic examined with unit checks and their enter information checked with information validation checks (e.g., Nice Expectations). The fashions should be examined for efficiency, but additionally for a scarcity of bias towards recognized teams of susceptible customers. Lastly, on the high of the pyramid, ML-Techniques want to check their efficiency with A/B checks earlier than they’ll change to make use of a brand new mannequin.
Lastly, we have to model ML artifacts in order that the operators of ML methods can safely replace and rollback variations of deployed fashions. System help for the push-button improve/downgrade of fashions is likely one of the holy grails of MLOps. However fashions want options to make predictions, so mannequin variations are linked to characteristic variations and fashions and options should be upgraded/downgraded synchronously. Fortunately, you don’t want a yr in rotation as a Google SRE to simply improve/downgrade fashions – platform help for versioned ML artifacts ought to make this a simple ML system upkeep operation.
Here’s a pattern of a few of the open-source ML methods obtainable constructed on the FTI structure. They’ve been constructed largely by practitioners and college students.
Batch ML Techniques
Actual-Time ML System
This text introduces the FTI pipeline structure for MLOps, which has empowered quite a few builders to effectively create and preserve ML methods. Based mostly on our expertise, this structure considerably reduces the cognitive load related to designing and explaining ML methods, particularly when in comparison with conventional MLOps approaches. In company environments, it fosters enhanced inter-team communication by establishing clear interfaces, thereby selling collaboration and expediting the event of high-quality ML methods. Whereas it simplifies the overarching complexity, it additionally permits for in-depth exploration of the person pipelines. Our purpose for the FTI pipeline structure is to facilitate improved teamwork and faster mannequin deployment, finally expediting the societal transformation pushed by AI.
Learn extra concerning the elementary ideas and parts that represent the FTI Pipelines structure in our full in-depth psychological map for MLOps.