

{kind=link}
Throughout the globe, people create myriad movies each day, together with user-generated reside streams, video-game reside streams, quick clips, motion pictures, sports activities broadcasts, and promoting. As a flexible medium, movies convey info and content material by varied modalities, similar to textual content, visuals, and audio. Growing strategies able to studying from these various modalities is essential for designing cognitive machines with enhanced capabilities to investigate uncurated real-world movies, transcending the constraints of hand-curated datasets.
Nonetheless, the richness of this illustration introduces quite a few challenges for exploring video understanding, notably when confronting extended-duration movies. Greedy the nuances of lengthy movies, particularly these exceeding an hour, necessitates subtle strategies of analyzing photos and audio sequences throughout a number of episodes. This complexity will increase with the necessity to extract info from various sources, distinguish audio system, determine characters, and keep narrative coherence. Moreover, answering questions based mostly on video proof calls for a deep comprehension of the content material, context, and subtitles.
In reside streaming and gaming video, further challenges emerge in processing dynamic environments in real-time, requiring semantic understanding and the flexibility to interact in long-term strategic planning.
In current instances, appreciable progress has been achieved in giant pre-trained and video-language fashions, showcasing their proficient reasoning capabilities for video content material. Nonetheless, these fashions are sometimes educated on concise clips (e.g., 10-second movies) or predefined motion courses. Consequently, these fashions might encounter limitations in offering a nuanced understanding of intricate real-world movies.
The complexity of understanding real-world movies entails figuring out people within the scene and discerning their actions. Moreover, pinpointing these actions is critical, specifying when and the way these actions happen. Moreover, it necessitates recognizing delicate nuances and visible cues throughout completely different scenes. The first goal of this work is to confront these challenges and discover methodologies straight relevant to real-world video understanding. The method entails deconstructing prolonged video content material into coherent narratives, subsequently using these generated tales for video evaluation.
Latest strides in Massive Multimodal Fashions (LMMs), similar to GPT-4V(ision), have marked important breakthroughs in processing each enter photos and textual content for multimodal understanding. This has spurred curiosity in extending the appliance of LMMs to the video area. The research reported on this article introduces MM-VID, a system that integrates specialised instruments with GPT-4V for video understanding. The overview of the system is illustrated within the determine beneath.
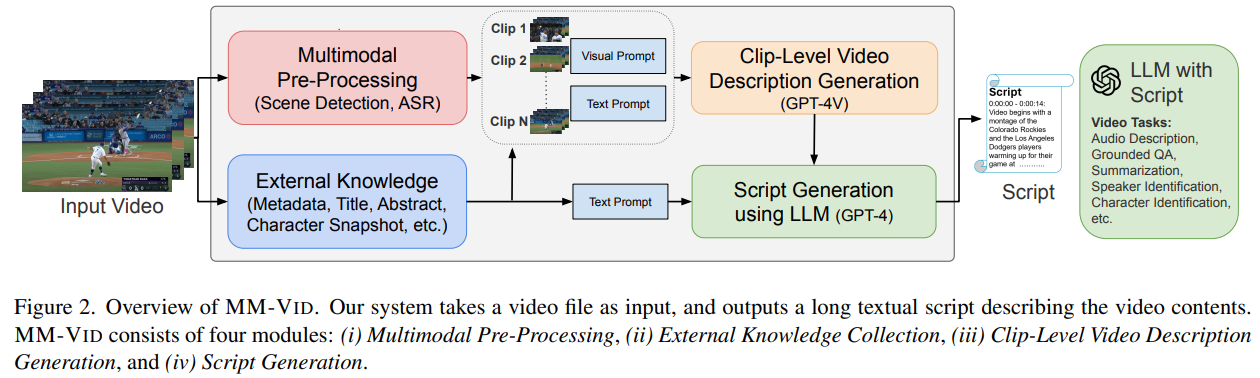
Upon receiving an enter video, MM-VID initiates multimodal pre-processing, encompassing scene detection and computerized speech recognition (ASR), to collect essential info from the video. Subsequently, the enter video is segmented into a number of clips based mostly on the scene detection algorithm. GPT-4V is then employed, using clip-level video frames as enter to generate detailed descriptions for every video clip. Lastly, GPT-4 produces a coherent script for your complete video, conditioned on clip-level video descriptions, ASR, and out there video metadata. The generated script empowers MM-VID to execute a various array of video duties.
Some examples taken from the research are reported beneath.
This was the abstract of MM-VID, a novel AI system integrating specialised instruments with GPT-4V for video understanding. If you’re and wish to be taught extra about it, please be happy to seek advice from the hyperlinks cited beneath.
Take a look at the Paper and Venture Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to affix our 33k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E-mail Publication, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
In case you like our work, you’ll love our publication..
We’re additionally on Telegram and WhatsApp.
Daniele Lorenzi acquired his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Info Expertise (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s presently working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embrace adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.