


Navigating the intricate world of machine studying isn’t any small feat, and measuring mannequin efficiency is undoubtedly one of the essential points. As we embark on this journey collectively by means of the realm of information science, we discover ourselves continuously pondering over questions like: How good is our mannequin? Is it performing nicely, and if not, how can we enhance it? And most significantly, how can we quantify its efficiency?
The solutions to those questions lie within the cautious use of efficiency metrics that assist us consider the success of our predictive fashions. On this weblog publish, we goal to delve into a few of these important instruments: ROC AUC, recall, precision, F1 rating, confusion matrices, and discovering problematic enter photos.
Receiver Working Attribute Space Below the Curve (ROC AUC) is a broadly used metric for evaluating the trade-off between true constructive price and false constructive price throughout completely different thresholds. It helps us perceive the general efficiency of our mannequin below various circumstances.
Precision and recall are two extremely informative metrics for issues the place the information is unbalanced. Precision permits us to know how lots of the constructive identifications have been really right, whereas recall helps us to know what number of precise positives have been recognized accurately.
Confusion matrices are a easy but highly effective visible illustration of a mannequin’s efficiency. This instrument helps us perceive the true positives, true negatives, false positives, and false negatives, thereby offering an outline of a mannequin’s accuracy.
This publish ought to function your information to unravel the complexities of mannequin efficiency and analysis metrics, offering insights into how one can successfully measure and enhance your machine studying fashions.
The way to get to the mannequin evaluations module
From the mannequin’s web page, choose “See variations desk”
From the variations desk, click on the “Calculate” button

{kind=link}
As soon as it is completed, click on “View Outcomes”

The evaluations module will load. You can even change the holdout set to guage on different datasets
How can I enhance mannequin efficiency for particular ideas?
Ideas that carry out nicely are typically those which can be annotated in photos photographed in a constant and distinctive manner.
Ideas that are inclined to carry out poorly are these:
- a) educated on information with inconsistent compositions;
- b) the photographs require exterior context (relationships to folks in portraits, and many others.); and/or,
- c) the subject material is refined.
Take note the mannequin has no idea of language; so, in essence, “what you see is what you get.”
Let’s take a case of a false constructive prediction made by a mannequin within the course of of coaching to acknowledge marriage ceremony imagery.
Right here is an instance of a picture of a married couple, which had a false constructive prediction for an individual holding a bouquet of flowers, despite the fact that there is no such thing as a bouquet within the photograph.
What’s happening right here?

A photograph’s composition and the mixture of parts therein may confuse a mannequin.
All the pictures under have been labeled with the ‘Bouquet_Floral_Holding’ idea.

On this very uncommon occasion, the picture in query has:
- A veiled bride
- The bride & groom kissing/their heads shut collectively
- Greenery over their heads
- Giant, recognizable flowers
The mannequin sees the mixture of all these particular person issues in a lot of photographs labeled ‘Bouquet_Floral_Holding’; and thus, that’s the prime end result.

One method to repair that is to slender the coaching information for ‘Bouquet_Floral_Holding’ to photographs through which the bouquet is the focus, quite than any occasion of the bouquet being held.
This manner, the mannequin can deal with the anchoring theme/object throughout the dataset extra simply.
What’s the ROC AUC rating, and the way does it relate to prediction accuracy?
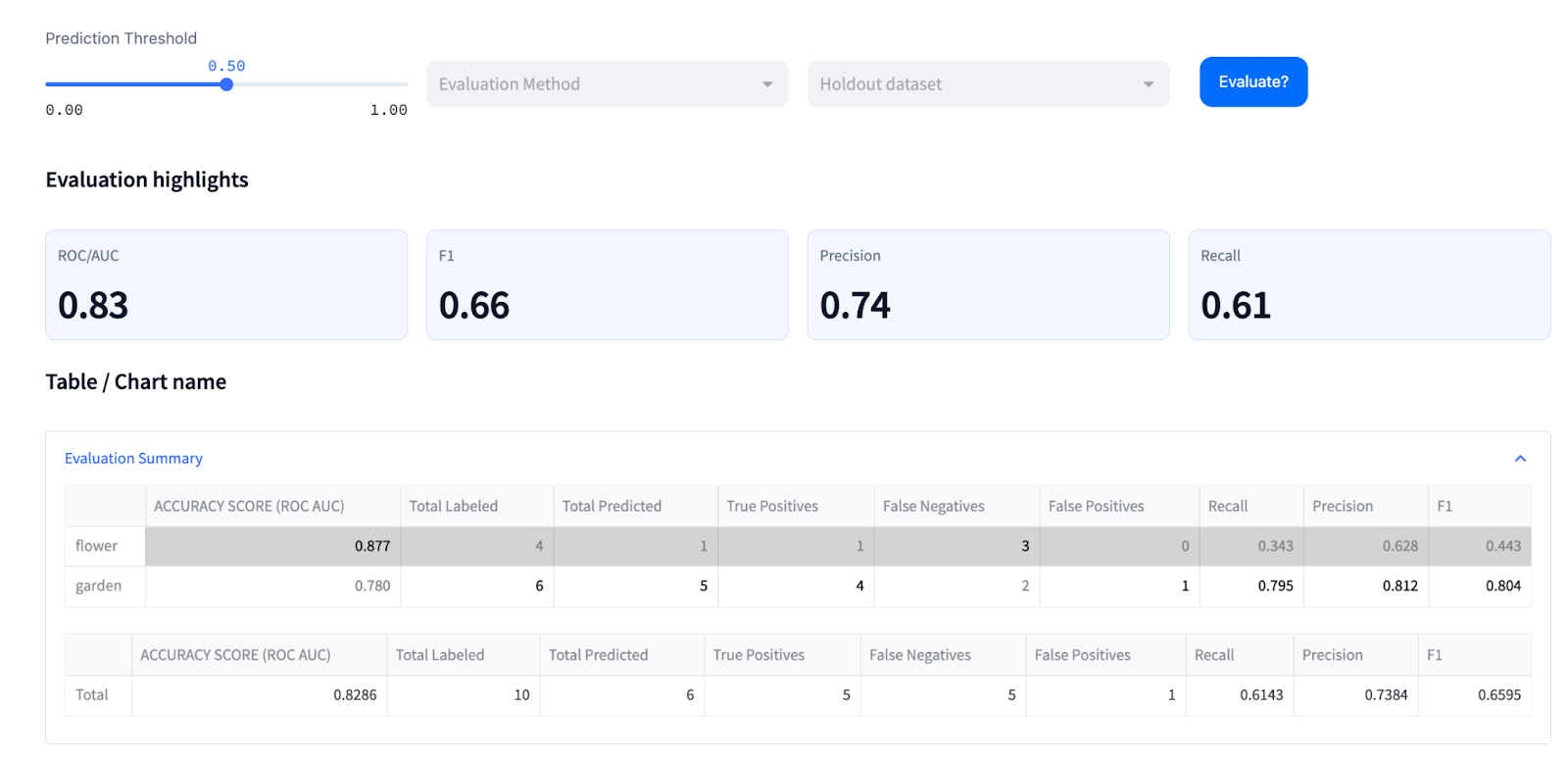
Above desk is out there in mannequin analysis web page within the legacy Clarifai’s Explorer UI
The ROC AUC (Idea Accuracy Rating) is the idea’s prediction efficiency rating, outlined by the world below the Receiver Working Attribute curve. This rating offers us an concept of how nicely we’ve got separated our completely different lessons, or ideas.
ROC AUC is generated by plotting the True Optimistic Fee (y-axis) in opposition to the False Optimistic Fee (x-axis) as you differ the brink for assigning observations to a given class. The AUC, or Area Under the Curve of those factors, is (arguably) one of the best ways to summarize a mannequin’s efficiency in a single quantity.
You may consider AUC as representing the chance {that a} classifier will rank a randomly chosen constructive statement greater than a randomly chosen unfavourable statement, and thus it’s a helpful metric even for datasets with extremely unbalanced lessons.
A rating of 1 represents an ideal mannequin; a rating of .5 represents a mannequin that may be no higher than random guessing, and this wouldn’t be appropriate for predictions and must be re-trained.
Observe that the ROC AUC is not depending on the prediction threshold.
How will we learn a concept-by-concept matrix?
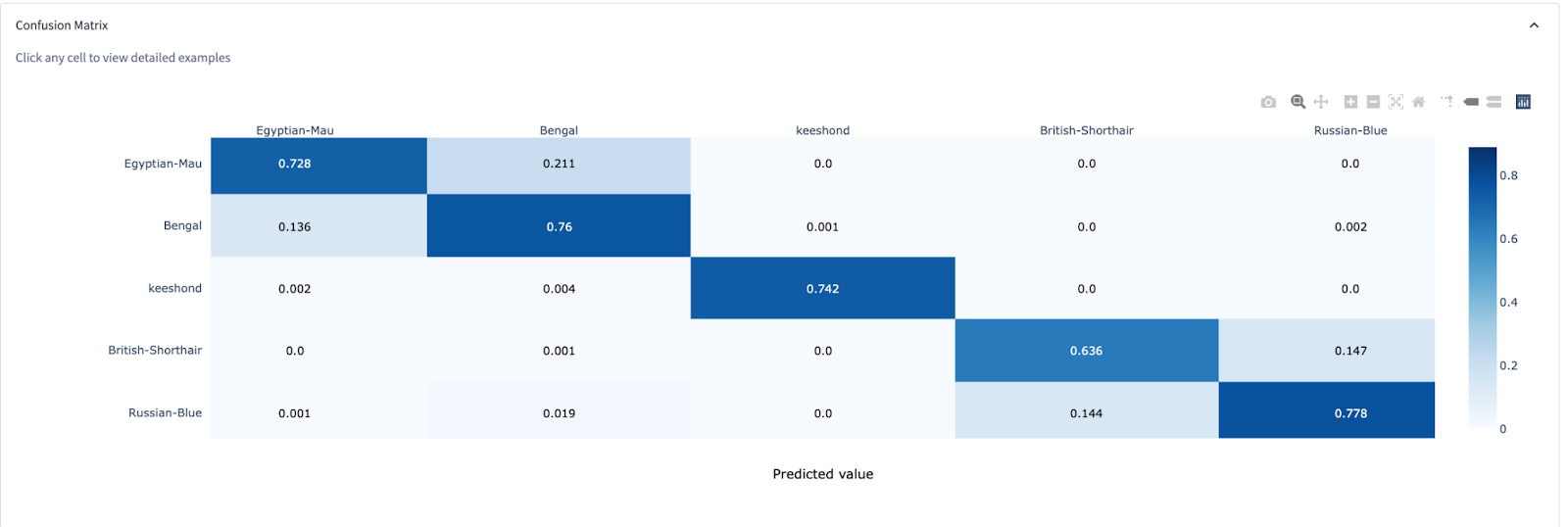
Above desk is out there in mannequin analysis web page within the legacy Clarifai’s Explorer UI
An idea-by-concept matrix is a graphic flattening of information to indicate what has been labeled for an idea. This instrument is one other manner of visualizing the efficiency of a mannequin.
It permits us to evaluation the place we see true positives, or accurately predicted inputs (the diagonal row). Merely put, this is a superb instrument for telling us the place our mannequin will get issues proper or mistaken.
Every row represents the subset of the check set that was really labeled as an idea, e.g., “canine.” As you go throughout the row, every cell reveals the variety of instances these photos have been predicted as every idea, famous by the column identify.
Together with AUC, what different insights can a confusion matrix present?
- Accuracy—Total, how usually is the mannequin right?
- Misclassification Fee—Total, how usually is it mistaken?
- True Optimistic Fee—When it is really sure, how usually does it predict sure?
- False Optimistic Fee—When it is really no, how usually does it predict sure?
- Specificity—When it is really no, how usually does it predict no?
- Precision—When it predicts sure, how usually is it right?
- Prevalence—How usually does the sure situation really happen in our pattern?
The diagonal cells characterize True Positives, i.e., accurately predicted inputs. You’d need this quantity to be as near the Complete Labeled as doable.
Relying on how your mannequin was educated, the off-diagonal cells may embody each right and incorrect predictions. In a non-mutually unique ideas surroundings, you may label a picture with greater than 1 idea.
For instance, a picture labeled as each “hamburger” and “sandwich” could be counted in each the “hamburger” row and the “sandwich” row. If the mannequin accurately predicts this picture to be each “hamburger” and “sandwich,” then this enter shall be counted in each on and off-diagonal cells.
Above desk is out there in mannequin analysis web page within the legacy Clarifai’s Explorer UI
It is a pattern confusion matrix for a mannequin. The Y-axis Precise Ideas are plotted in opposition to the X-axis Predicted Ideas. The cells show common prediction chance for a sure idea, and for a gaggle of photos that have been labeled as a sure idea.
The diagonal cells are the common chance for true positives, and any cells off the horizontal cells comprise the common chance for non-true positives. From this confusion matrix, we are able to see that every idea is distinct from each other, with a couple of areas of overlap, or clustering.
Ideas that co-occur, or are related, might seem as a cluster on the matrix.
How can I enhance a mannequin by drilling right down to “problematic cells” in a confusion matrix?
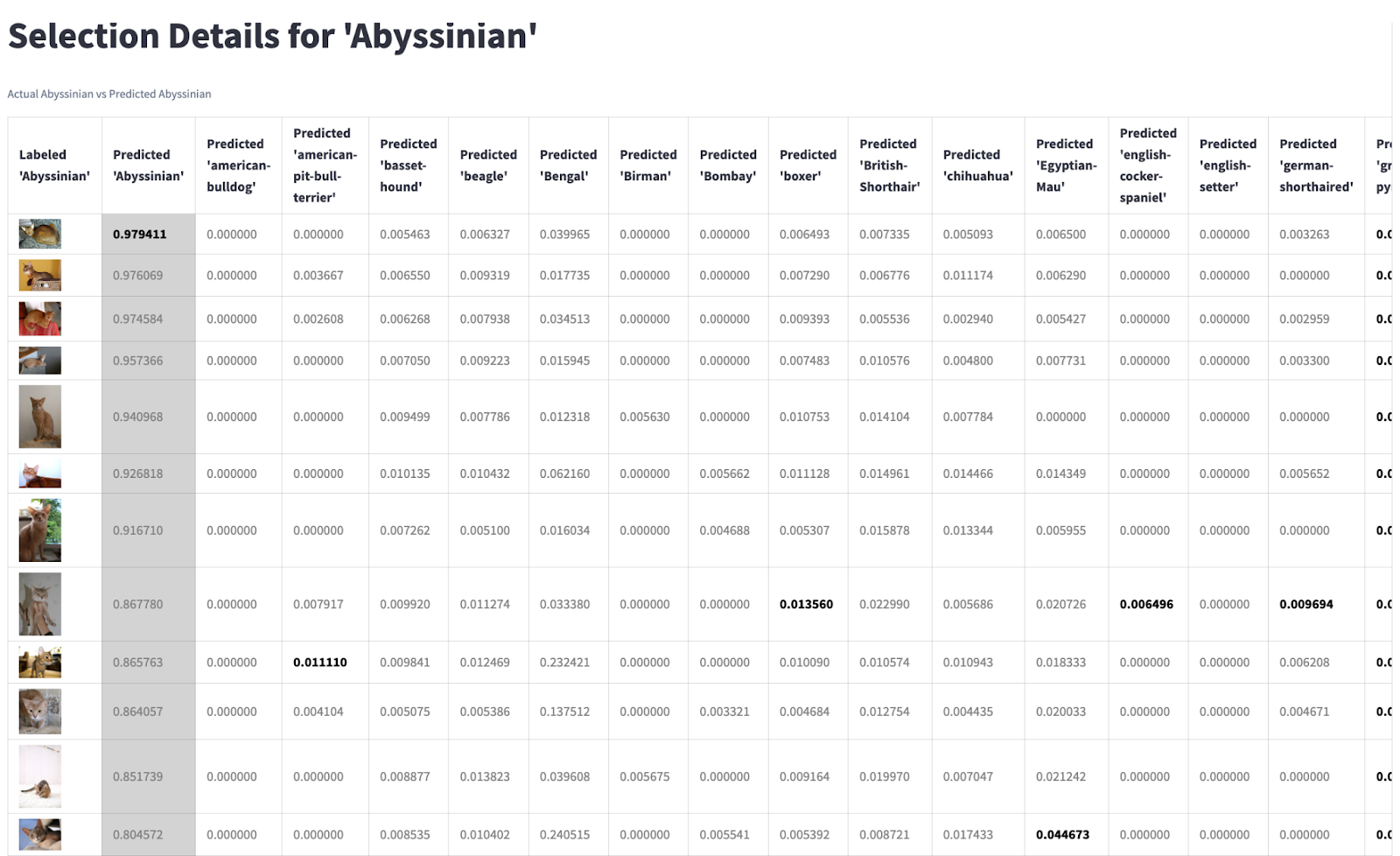
What’s the significance of recall and precision price?
Recall price refers back to the proportion of the pictures labeled because the idea that have been predicted because the idea. It’s calculated as True Positives divided by Complete Labeled. Also referred to as “sensitivity” or “true constructive price.”
Precision price refers back to the proportion of the pictures predicted as an idea that had been really labeled because the idea. It’s calculated as True Positives divided by Complete Predicted. Also referred to as “constructive predictive worth.”
You may consider precision and recall within the context of what we wish to calibrate our mannequin in the direction of. Precision and recall are inversely correlated; so, in the end the ratio of false positives to false negatives is as much as the shopper based on their aim.
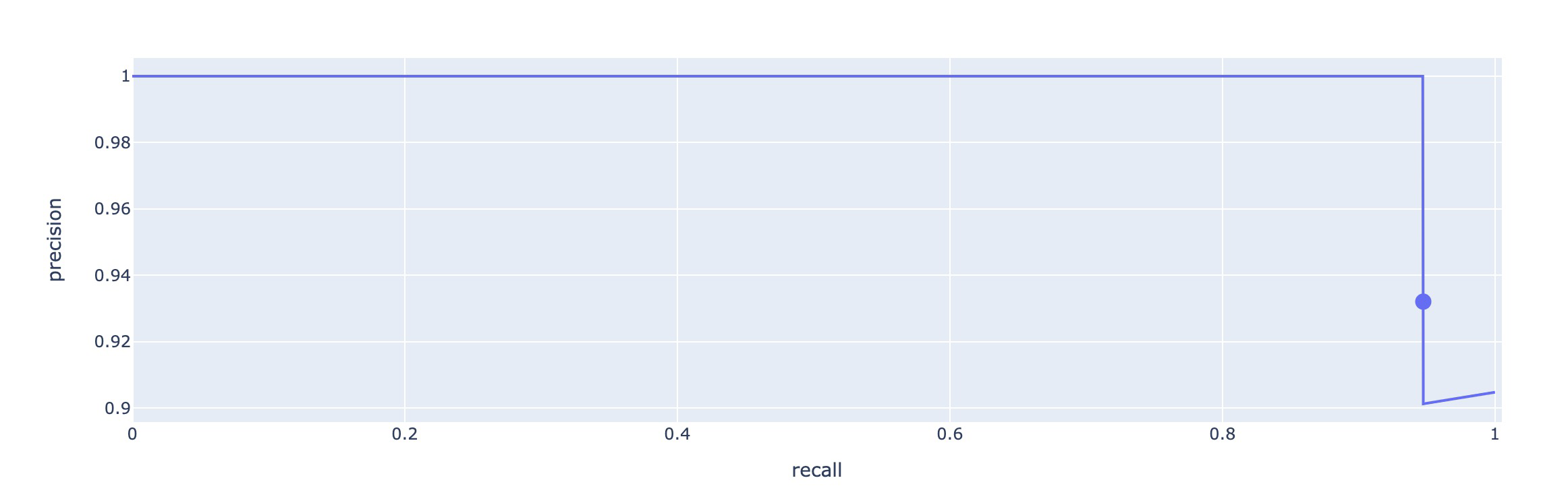
We’re asking one of many following of our mannequin:
- That the guesses are right, whereas lacking some ideas (excessive precision);
Or,
- That almost all issues are thought-about to be predicted as an idea, whereas having some mistaken predictions (excessive recall).
Instance:
Precision = tp÷(tp+fp)
I assume for X, and my guess is right, though I’ll miss one other X.
Or,
Recall = tp ÷ (tp+fn)
I assume all of the X as X, however often predict different topics that aren’t X as X.
How will we select a prediction threshold?
A threshold is the “candy spot” numerical rating that’s depending on the target of your prediction for recall and/or precision. In apply, there are a number of methods to outline “accuracy” on the subject of machine studying, and the brink is the quantity we use to gauge our preferences.
You may be questioning how you need to set your classification threshold, as soon as you’re prepared to make use of it to foretell out-of-sample information. That is extra of a enterprise determination, in that you must determine whether or not you’ll quite reduce your false constructive price or maximize your true constructive price.
If our mannequin is used to foretell ideas that result in a high-stakes determination, like a analysis of a illness or moderation for security, we would think about a couple of false positives as forgivable (higher to be protected than sorry!). On this case, we would need excessive precision.
If our mannequin is used to foretell ideas that result in a suggestion or versatile consequence, we would need excessive recall in order that the mannequin can enable for exploration.
In both state of affairs, we’ll wish to guarantee our mannequin is educated and examined with information that greatest displays its use case.
As soon as we’ve got decided the aim of our mannequin (excessive precision or excessive recall), we are able to use check information that our mannequin has by no means seen earlier than to guage how nicely our mannequin predicts based on the requirements we’ve got set.
As soon as a mannequin is educated and evaluated, how will we decide its accuracy?
The aim of any mannequin is to get it to see the world as you see it.
In multi-class classification, accuracy is decided by the variety of right predictions divided by the whole variety of examples.
In binary classification, or for mutually unique lessons, accuracy is decided by the variety of true positives added to the variety of true negatives, divided by the whole variety of examples.
As soon as we’ve got established the aim we’re working in the direction of with the bottom reality, we start to evaluate your mannequin’s prediction returns. It is a fully subjective query, and most shoppers merely wish to know that their fashions will carry out to their requirements as soon as it’s in the true world.
We start by operating a check set of photos by means of the mannequin and studying their precision and recall scores. The check set of photos must be:
- a) inputs that the mannequin has not been educated with, and;
- b) be the identical form of information we might count on to see within the mannequin’s explicit use case.
As soon as we’ve got our precision or recall scores, we’ll examine these to the mannequin’s recall or precision thresholds for .5 and .8, respectively.